Healthcare and life sciences AI is moving from labels and synthetic data to real-world data. The moat isn’t simply collecting this real-world data but applying the domain expertise to refine it.
Through our portfolio company Integral, we’ve had a view from the infrastructure layer of how labs and human-data companies are thinking about post-training data. This frontier-lab lens of asking “What data will frontier labs pay for?” has been the best forcing function we've found for thinking about data moats for startups we work with. It reveals what frontier labs structurally can’t get (private workflow data inside deployed products, exclusive partnerships) and where startups can build defensibility.
Three kinds of post-training data, and why healthcare is moving to real-world data
We drew on Sid Potdar's three buckets of post-training human data to anchor how we think about post-training data in healthcare:
- Annotations on live model output
- From-scratch synthetic environments
- Real-world data
By “real-world data”, we mean any data generated as the exhaust of activity (clinical notes, patient/provider voice interactions, decision traces from deployed software), not data manufactured only to train models. This is broader than the FDA's regulatory definition of real-world data (RWD) in life sciences (EHR, claims, registries) and includes things like workflow exhaust from deployed products, AI scribe audio, and clinician edits on model output.
Healthcare is moving to real-world data for two main reasons. First, the verification problem is structurally different from areas like coding. Whether a clinical note got the diagnosis right or a prior auth matched medical necessity only shows up downstream in clinician edits, payer adjudications, and reimbursement outcomes. Second, healthcare is a low-veracity domain. The underlying logic is heterogeneous (e.g., each payer interprets the same InterQual rules differently) so a synthetic environment can’t capture the real distribution of potential outcomes. Both problems mean Buckets 1 and 2 fall short on their own. Labels can’t carry the downstream signal verification needs and synthetic environments can’t capture the customer-by-customer variation in workflow logic.
Healthcare-specific examples for each bucket are below, with the nuance inside real-world data:

Bucket 1 is table stakes for most companies. The tooling is more mature, but what varies is whether the underlying task has a measurable answer (prior auth vs. scribes above). More teams are spinning up custom in-house annotation UIs and recruiting experts (or using founder’s expertise) because that’s faster than waiting on SOW from a vendor.
For Bucket 2, the horizontal infrastructure layer is generalist, and new tooling is making environments easier to spin up (e.g., Prime Intellect’s environments hub). The healthcare-specific players typically use Bucket 2 as a wedge into something more durable and scalable. Michael Wornow and team took the HealthAdminBench playbook (Stanford) into Kinetic Systems, going directly after Bucket 3 with computer-use agents inside payer and provider workflows. Lumos is moving into Bucket 3 by capturing click-by-click traces of expert workflows as training trajectories for agents.
We split Bucket 3 into two types of real-world data:
- Outcomes: What happened without all of the reasoning behind it. Claims, EHR exports, imaging data, biobank samples. Either already in your possession, purchased from a vendor like Protege, or licensed directly from data originators.
- Outcomes + Reasoning: The result plus the decision trace that produced it, which includes inputs considered, rules applied, exceptions, and overrides. Foundation Capital calls this a “context graph” or a living record of decisions captured at decision time rather than reconstructed via ETL.
Within the outcomes + reasoning mode, we split system-of-record (Canvas) from embedded-in-workflow (Dart) mostly to think about competitive positioning. We don’t see many startups building new systems of record in healthcare or life sciences in 2026, but how they compete against existing systems of record is important to be aware of.
Worked Example: Scientific Lab Data
Take scientific lab data as a concrete example. It shows how all five sub-buckets look in practice.
- Bucket 1. Scientists look at LLM-generated outputs (literature reviews, hypotheses, methodology drafts) and rate good/bad/why.
- Bucket 2. A company builds a synthetic version of a workflow like sc-RNA-seq, trying to anticipate every edge case 20 PhDs can think of.
- Bucket 3:
- Outcomes: You go to universities, hospitals, registries and acquire the data that already exists (lab notebooks, unpublished negative results). The data is real but it’s more what happened than why it happened (although you can infer some of the why).
- Outcomes + Reasoning (System of Record): Benchling is the system of record in this space. This is useful as a comparison point, even though most startups won’t build a new system of record. Their recent "AI Scientist" essay positions the structured experimental data, workflows, and decision logs they’ve captured over a decade as the foundation for AI.
- Outcomes + Reasoning (Embedded in Workflow): You build a deployed product that observes scientific execution as it happens (e.g., Transfyr). Reasoning, decision traces, and protocol deviations are all captured as a first-class data layer because the product was built from day one to do so.
A single company can move through all of these as it builds toward a defensible data position. You can start with off-the-shelf models on a task you know well and grade the output, hill-climb on benchmarks or RL environments, then ask what real-world data you need for the next leap in performance. Then the question for any Bucket 3 play becomes: is outcomes-only data enough to reach the model performance your task needs? Or do you need to deploy something that captures reasoning as it happens?
In practice, outcomes-only data is enough when the task is bounded and the signal already lives in what already exists (imaging classification, structured prediction from claims, certain biomarker work for drug response). You need outcomes + reasoning when the task requires reasoning, when the workflow logic varies across customers (payer-specific PA rules, institution-specific escalation paths), or when the verifier itself lives inside a deployed product (a paid claim, an accepted code, a clinician-confirmed diagnosis).
Whether you then sell that data to a lab, train your own model, or do both is a business-model question for another post!
Real-world data alone is a starting point. Utilizing domain expertise to refine real-world data is the moat.
Once you have the real-world data, the refinement work is where the moat lives. As Shubh (Integral CEO) has written, the easy data has already been trained on. The next trillion tokens are regulated and sensitive, and the bottleneck is usability.
With this frontier-lab lens, we’ve been working closely with Integral to understand what this looks like in practice. Integral has built the independent privacy and sanitization layer for AI data workflows. This layer includes entity-preserving methods that keep the longitudinal record intact while the dataset carries a defensible re-identification posture, across structured data, text, images, and speech. Integral sits on both sides to help frontier labs buy compliant real-world data and data originators/suppliers monetize their data.
Working with Integral made clear where the work compounds. It’s not only the data pipeline itself (table stakes), but the domain expertise to ask the right questions at every layer of the stack.
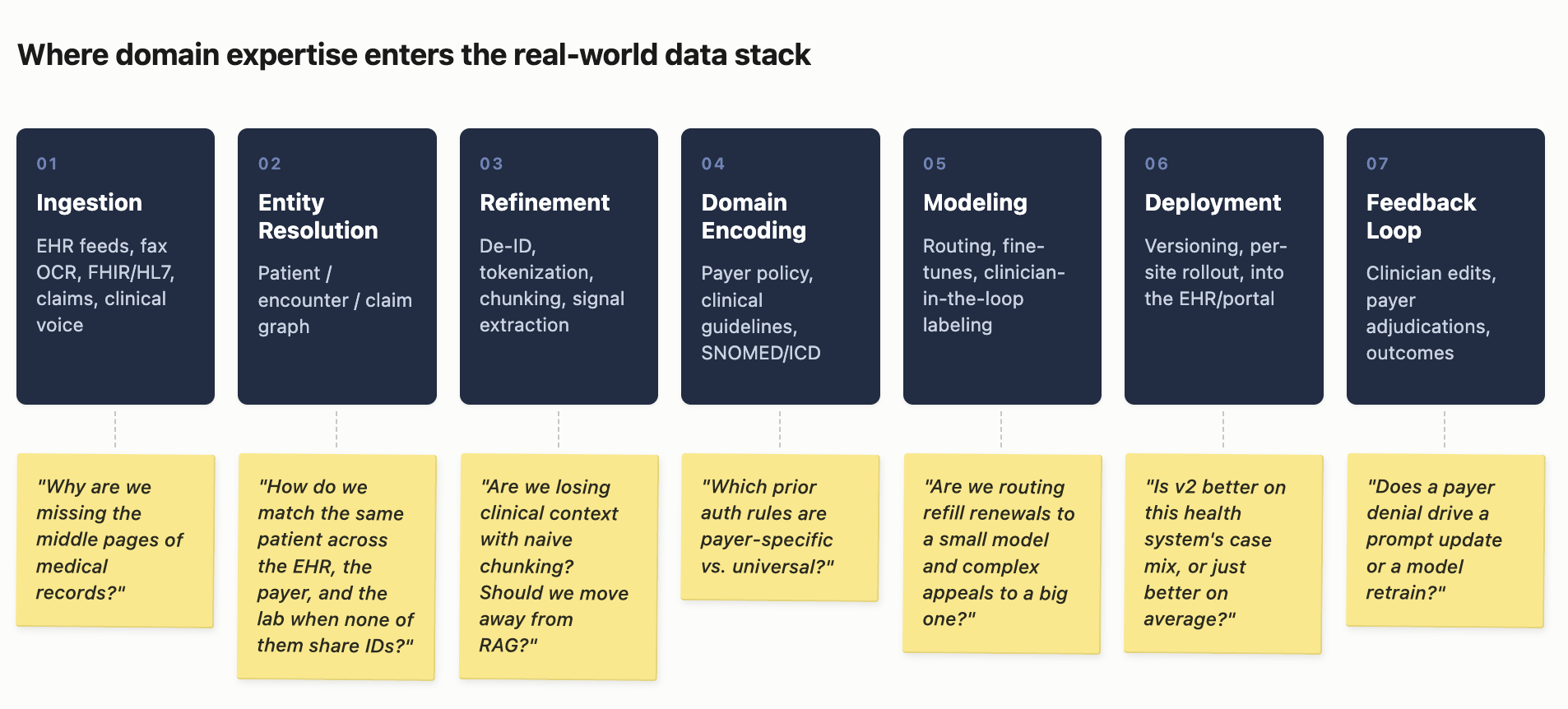
Every step has decisions only a domain expert can make. Why are we missing the middle pages of medical records? Should we route refill renewals to a small model and complex appeals to a big one? Is v2 better on this health system’s case mix, or just better on average? You can’t buy answers to these questions. The moat is the domain expertise at every layer of the stack for what gets included, what gets cut, and how things are weighted.
What we anticipate moving forward
1. The application layer will continue to mature beyond prompt engineering. Most app-layer companies aren’t training their own models, but they’re not just calling frontier APIs either. They’re building production loops that turn deployed traces into reward signal, evals tuned to their domain, and fine-tuning where business performance and outcomes warrant it. Charlie O’Neill describes this shift from his vantage point at Baseten. Companies will build a deeper engineering stack underneath the product that captures reward signal from the workflow and turns it into training data.
2. Multi-modal data and models will win in healthcare. Healthcare is inherently multi-modal (clinical notes, radiology, pathology, audio, structured labs, time-series telemetry, genomics, etc.). Most frontier models today are single-modal or weakly multi-modal, and public data doesn’t align across modalities at the patient level. The app-layer companies capturing multi-modal data inside the workflow, where text, image, audio, and structured data are already linked to the same patient, encounter, and decision have a dataset labs can’t easily reconstruct from the outside.
3. Domain expertise is shifting. Virtue was founded on the belief that domain-specific expertise is essential to building healthcare companies, and we wanted to bring that same expertise as investors. What domain expertise means has shifted over the last five years. It used to be primarily about relationships with buyers and knowing how to play the game within a broken system. Those still matter, but they are table stakes now. Teams now need more expertise in data engineering and the data-quality judgment that comes with it, breaking workflows down into automatable steps, and knowing what "good" looks like for AI outputs in domains like healthcare where outputs are hard to verify.
We’d love to chat more with founders who are building here, AI folks getting into healthcare, and anyone with real-world data assets they think are valuable but untapped!
Thanks to many friends who have provided feedback in writing this post! S/O Shubh Sinha, Veeraj Mehta, Aaryan Shah, Michael Wornow, Samir Unni, and many others.
Additional Reading
- Sid Potdar — Data Labeling and Other Euphemisms
- Foundation Capital — AI’s trillion-dollar opportunity: Context graphs
- Jamin Ball — Long Live Systems of Record (Clouded Judgement)
- Benchling — An AI Scientist that deserves the name
- Sean Cai — An AI Bubble is a Human Data Problem
- HOMER-1: The Clinical AI Machine [Dart Health]
- Sean Cai — Selling Data & RL Envs to AI Labs (Chris Barber interview)
- Charlie O'Neill (Baseten) — Why every serious AI company is training its own model
- Jason Wei — Asymmetry of verification and verifier’s rule
- Shubh Sinha (Integral) — Data Privacy Programs for AI
- HealthAdminBench (Stanford)
- Biomni-R0 (Stanford SNAP) — RL-trained biology agent
- Lumos MedPI — Clinical evaluation framework